Edge Cluster Monitoring with Kube-Prometheus-Stack, Thanos, and Cilium

In my latest homelab project, I set out to bring observability to the two edge Kubernetes clusters I maintain. One runs on a trio of Raspberry Pi nodes, the other on Oracle Cloud’s always-free tier with four nodes. Both are tight on resources and not well-suited to running a full-blown Kube-Prometheus-Stack. My goal was simple: centralize monitoring into my more capable "production" cluster—where compute and storage are far more plentiful—while keeping the edge clusters as lightweight as possible. That meant rethinking how Prometheus and Thanos were deployed, and figuring out just how minimal an edge monitoring footprint could be while still getting meaningful metrics.
Architecture
When it comes to forwarding metrics from edge clusters to a central store, two common approaches with Thanos are using the Thanos Sidecar alongside Prometheus, or pushing metrics via remote write to a central Thanos Receive endpoint. The sidecar method allows Prometheus to write blocks locally and then upload them to object storage, where they can be picked up by Thanos Query and Compactor later. This has the benefit of buffering metrics even when connectivity is spotty and keeps Prometheus fully self-contained. On the other hand, remote write to Thanos Receive pushes metrics in near real-time to the central cluster, skipping local storage entirely. While this can reduce resource usage on edge clusters, it comes with trade-offs: remote write doesn't deduplicate like the sidecar does, and missing labels or dropped samples can affect alerting and long-term queries. In my setup, I went with the Thanos Sidecar model for reliability, better deduplication, and compatibility with object storage, which also made block compaction and retention easier to manage centrally.
Here's what my solution ended up looking like (RPI cluster removed for simplicity):
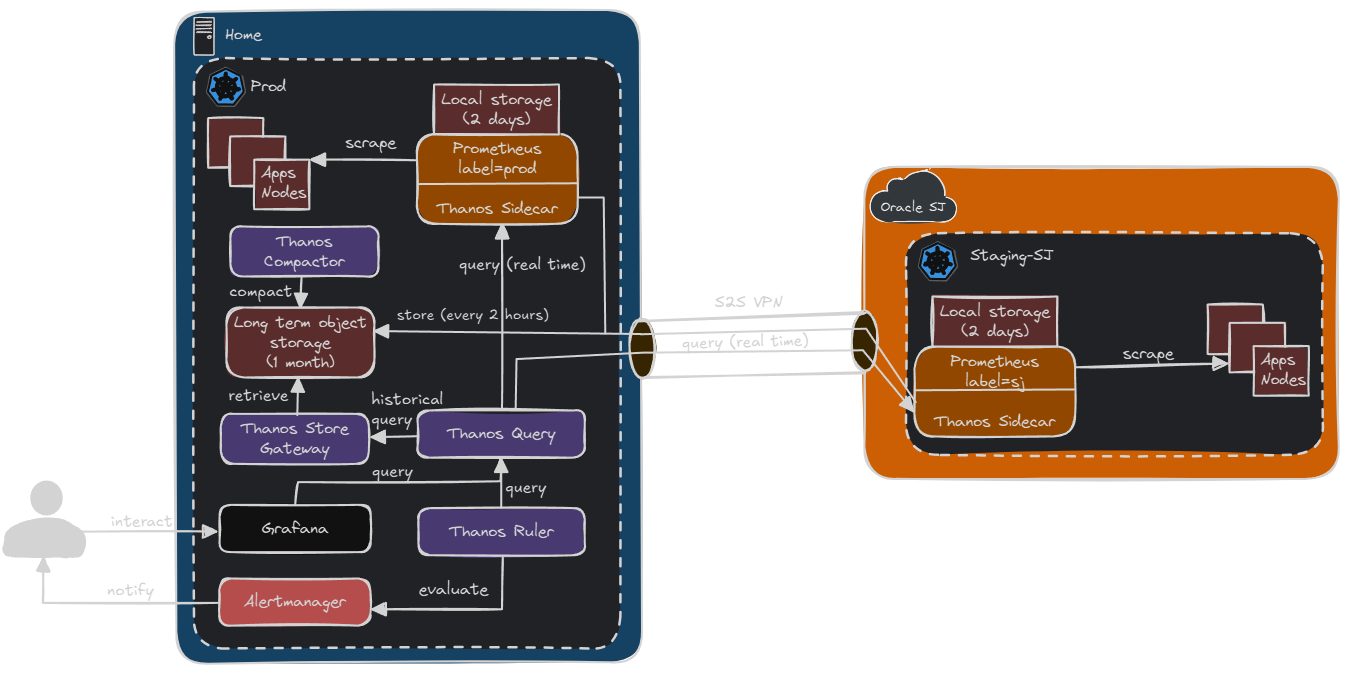
Cilium
One of the most seamless parts of this project was leveraging Cilium ClusterMesh to enable cross-cluster discovery of Thanos Sidecars. Since ClusterMesh establishes native Kubernetes service connectivity across clusters, I was able to expose the kube-prometheus-stack-thanos-discovery service from my edge clusters to the central cluster simply by labeling it and my central cluster with service.cilium.io/global: "true". This meant that my central Thanos Query could automatically discover and scrape sidecars from remote clusters without requiring extra networking plumbing, VPNs, or manual service entries. ClusterMesh essentially made my separate Kubernetes clusters behave like one large mesh, and that simplicity was a huge win for keeping the Thanos integration lightweight and dynamic.
⚠️ Warning
As of Cilium 1.17, endpoint slice synchronization is in beta and must be explicitly enable to perform discovery across clusters with headless services!
Deploying Kube-Prometheus-Stack
For all my deployments, I am using Flux, hence the HelmRelease CRD. The full source is always available in my homelab repository (you can find my Grafana values there, if you're interested).
Central Cluster
In this deployment, we're going to enable Thanos Ruler, Prometheus, and Alertmanager.
---
apiVersion: helm.toolkit.fluxcd.io/v2
kind: HelmRelease
metadata:
name: kube-prometheus-stack
spec:
values:
defaultRules:
create: true
rules:
etcd: false
alertmanager:
config:
global:
slack_api_url: "${SECRET_PROMETHEUS_DISCORD_ALERTS_WEBHOOK}"
resolve_timeout: 5m
receivers:
- name: "null"
- name: "pushover"
pushover_configs:
- send_resolved: true
user_key: "${SECRET_PUSHOVER_USER_KEY}"
token: "${SECRET_ALERTMANAGER_PUSHOVER_TOKEN}"
title: |-
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if ne .CommonAnnotations.summary ""}}{{ .CommonAnnotations.summary }}{{ else }}{{ .CommonLabels.alertname }}{{ end }}
message: >-
{{ range .Alerts -}}
**Alert:** {{ .Annotations.title }}{{ if .Labels.severity }} - `{{ .Labels.severity }}`{{ end }}
**Description:** {{ if ne .Annotations.description ""}}{{ .Annotations.description }}{{else}}N/A{{ end }}
**Details:**
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}`
{{ end }}
{{ end }}
- name: "discord"
slack_configs:
- channel: "#prometheus-alerts"
icon_url: https://avatars3.githubusercontent.com/u/3380462
username: "prom-alert-bot"
send_resolved: true
title: |-
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ if ne .CommonAnnotations.summary ""}}{{ .CommonAnnotations.summary }}{{ else }}{{ .CommonLabels.alertname }}{{ end }}
text: >-
{{ range .Alerts -}}
**Alert:** {{ .Annotations.title }}{{ if .Labels.severity }} - `{{ .Labels.severity }}`{{ end }}
**Description:** {{ if ne .Annotations.description ""}}{{ .Annotations.description }}{{else}}N/A{{ end }}
**Details:**
{{ range .Labels.SortedPairs }} • *{{ .Name }}:* `{{ .Value }}`
{{ end }}
{{ end }}
route:
group_by: ["alertname", "job"]
group_wait: 30s
group_interval: 5m
repeat_interval: 6h
receiver: "null"
routes:
- receiver: "null"
matchers:
- alertname =~ "InfoInhibitor"
- alertname =~ "Watchdog"
- receiver: "discord"
match_re:
severity: critical|warning|error
continue: true
- receiver: "pushover"
match_re:
severity: critical|warning|error
continue: true
inhibit_rules:
- source_match:
severity: "critical"
target_match:
severity: "warning"
equal: ["alertname", "namespace"]
ingress:
enabled: true
pathType: Prefix
ingressClassName: "traefik"
hosts:
- &host-alert-manager "alert-manager.${SECRET_DOMAIN}"
tls:
- hosts:
- *host-alert-manager
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: "ceph-block"
resources:
requests:
storage: 6Gi
nodeExporter:
enabled: true
grafana:
enabled: false
kube-state-metrics:
metricLabelsAllowlist:
- "pods=[*]"
- "deployments=[*]"
- "persistentvolumeclaims=[*]"
prometheus:
monitor:
enabled: true
relabelings:
- action: replace
regex: ^(.*)$
replacement: $1
sourceLabels: ["__meta_kubernetes_pod_node_name"]
targetLabel: kubernetes_node
kubelet:
enabled: true
serviceMonitor:
metricRelabelings:
# Remove duplicate labels
- action: keep
sourceLabels: ["__name__"]
regex: (apiserver_audit|apiserver_client|apiserver_delegated|apiserver_envelope|apiserver_storage|apiserver_webhooks|authentication_token|cadvisor_version|container_blkio|container_cpu|container_fs|container_last|container_memory|container_network|container_oom|container_processes|container|csi_operations|disabled_metric|get_token|go|hidden_metric|kubelet_certificate|kubelet_cgroup|kubelet_container|kubelet_containers|kubelet_cpu|kubelet_device|kubelet_graceful|kubelet_http|kubelet_lifecycle|kubelet_managed|kubelet_node|kubelet_pleg|kubelet_pod|kubelet_run|kubelet_running|kubelet_runtime|kubelet_server|kubelet_started|kubelet_volume|kubernetes_build|kubernetes_feature|machine_cpu|machine_memory|machine_nvm|machine_scrape|node_namespace|plugin_manager|prober_probe|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|registered_metric|rest_client|scrape_duration|scrape_samples|scrape_series|storage_operation|volume_manager|volume_operation|workqueue)_(.+)
- action: replace
sourceLabels: ["node"]
targetLabel: instance
# Drop high cardinality labels
- action: labeldrop
regex: (uid)
- action: labeldrop
regex: (id|name)
- action: drop
sourceLabels: ["__name__"]
regex: (rest_client_request_duration_seconds_bucket|rest_client_request_duration_seconds_sum|rest_client_request_duration_seconds_count)
kubeApiServer:
enabled: true
serviceMonitor:
metricRelabelings:
# Remove duplicate metrics
- action: keep
sourceLabels: ["__name__"]
regex: (aggregator_openapi|aggregator_unavailable|apiextensions_openapi|apiserver_admission|apiserver_audit|apiserver_cache|apiserver_cel|apiserver_client|apiserver_crd|apiserver_current|apiserver_envelope|apiserver_flowcontrol|apiserver_init|apiserver_kube|apiserver_longrunning|apiserver_request|apiserver_requested|apiserver_response|apiserver_selfrequest|apiserver_storage|apiserver_terminated|apiserver_tls|apiserver_watch|apiserver_webhooks|authenticated_user|authentication|disabled_metric|etcd_bookmark|etcd_lease|etcd_request|field_validation|get_token|go|grpc_client|hidden_metric|kube_apiserver|kubernetes_build|kubernetes_feature|node_authorizer|pod_security|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|registered_metric|rest_client|scrape_duration|scrape_samples|scrape_series|serviceaccount_legacy|serviceaccount_stale|serviceaccount_valid|watch_cache|workqueue)_(.+)
# Drop high cardinality labels
- action: drop
sourceLabels: ["__name__"]
regex: (apiserver|etcd|rest_client)_request(|_sli|_slo)_duration_seconds_bucket
- action: drop
sourceLabels: ["__name__"]
regex: (apiserver_response_sizes_bucket|apiserver_watch_events_sizes_bucket)
kubeControllerManager:
enabled: true
endpoints: &cp
- 172.16.20.105
- 172.16.20.106
- 172.16.20.107
serviceMonitor:
metricRelabelings:
# Remove duplicate metrics
- action: keep
sourceLabels: ["__name__"]
regex: "(apiserver_audit|apiserver_client|apiserver_delegated|apiserver_envelope|apiserver_storage|apiserver_webhooks|attachdetach_controller|authenticated_user|authentication|cronjob_controller|disabled_metric|endpoint_slice|ephemeral_volume|garbagecollector_controller|get_token|go|hidden_metric|job_controller|kubernetes_build|kubernetes_feature|leader_election|node_collector|node_ipam|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|pv_collector|registered_metric|replicaset_controller|rest_client|retroactive_storageclass|root_ca|running_managed|scrape_duration|scrape_samples|scrape_series|service_controller|storage_count|storage_operation|ttl_after|volume_operation|workqueue)_(.+)"
kubeScheduler:
enabled: true
endpoints: *cp
serviceMonitor:
metricRelabelings:
# Remove duplicate metrics
- action: keep
sourceLabels: ["__name__"]
regex: "(apiserver_audit|apiserver_client|apiserver_delegated|apiserver_envelope|apiserver_storage|apiserver_webhooks|authenticated_user|authentication|disabled_metric|go|hidden_metric|kubernetes_build|kubernetes_feature|leader_election|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|registered_metric|rest_client|scheduler|scrape_duration|scrape_samples|scrape_series|workqueue)_(.+)"
kubeProxy:
enabled: false
kubeEtcd:
enabled: true
endpoints: *cp
service:
enabled: true
port: 2381
targetPort: 2381
serviceMonitor:
scheme: https
insecureSkipVerify: false
serverName: localhost
caFile: /etc/prometheus/secrets/etcd-certs/etcd-ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/etcd-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-client-key.key
prometheus:
ingress:
enabled: true
pathType: Prefix
ingressClassName: "traefik"
hosts:
- &host-prometheus "prometheus.${SECRET_DOMAIN}"
tls:
- hosts:
- *host-prometheus
thanosService:
enabled: true
annotations:
service.cilium.io/global: "true"
thanosServiceMonitor:
enabled: true
thanosIngress:
enabled: true
pathType: Prefix
ingressClassName: "traefik"
hosts:
- &host-thanos-sidecar "thanos-sidecar.${SECRET_DOMAIN}"
tls:
- hosts:
- *host-thanos-sidecar
prometheusSpec:
replicas: 3
replicaExternalLabelName: __replica__
externalLabels:
cluster: prod
ruleSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
probeSelectorNilUsesHelmValues: false
retention: 2d
retentionSize: 50GB
enableAdminAPI: true
walCompression: true
ruleSelector:
matchLabels:
role: some-fake-nonexistent-role
secrets:
- etcd-certs
thanos:
image: quay.io/thanos/thanos:v0.38.0
# renovate: datasource=docker depName=quay.io/thanos/thanos
version: "v0.38.0"
objectStorageConfig:
secret:
type: S3
config:
insecure: true
# bucket: ""
# endpoint: ""
# region: ""
# access_key: ""
# secret_key: ""
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ceph-block
resources:
requests:
storage: 60Gi
additionalPrometheusRulesMap:
oom-rules:
groups:
- name: oom
rules:
- alert: OomKilled
annotations:
summary: Container {{ $labels.container }} in pod {{ $labels.namespace }}/{{ $labels.pod }} has been OOMKilled {{ $value }} times in the last 10 minutes.
expr: (kube_pod_container_status_restarts_total - kube_pod_container_status_restarts_total offset 10m >= 1) and ignoring (reason) min_over_time(kube_pod_container_status_last_terminated_reason{reason="OOMKilled"}[10m]) == 1
labels:
severity: critical
thanosRuler:
enabled: true
ingress:
enabled: true
pathType: Prefix
ingressClassName: "traefik"
hosts:
- &host-thanos-ruler "thanos-ruler.${SECRET_DOMAIN}"
tls:
- hosts:
- *host-thanos-ruler
thanosRulerSpec:
replicas: 3
image:
# renovate: datasource=docker depName=quay.io/thanos/thanos
registry: quay.io
repository: thanos/thanos
tag: v0.38.0
alertmanagersConfig:
secret:
alertmanagers:
- api_version: v2
static_configs:
- kube-prometheus-stack-alertmanager:9093
scheme: http
timeout: 10s
objectStorageConfig:
secret:
type: S3
config:
insecure: true
# bucket: ""
# endpoint: ""
# region: ""
# access_key: ""
# secret_key: ""
queryEndpoints:
["dnssrv+_http._tcp.thanos-query.monitoring.svc.cluster.local"]
storage:
volumeClaimTemplate:
spec:
storageClassName: "ceph-block"
resources:
requests:
storage: 6Gi
valuesFrom:
# Thanos Sidecar
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.bucket
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_NAME
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.endpoint
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_HOST
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.region
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_REGION
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.access_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_ACCESS_KEY_ID
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.secret_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_SECRET_ACCESS_KEY
# Thanos Ruler
- targetPath: thanosRuler.thanosRulerSpec.objectStorageConfig.secret.config.bucket
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_NAME
- targetPath: thanosRuler.thanosRulerSpec.objectStorageConfig.secret.config.endpoint
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_HOST
- targetPath: thanosRuler.thanosRulerSpec.objectStorageConfig.secret.config.region
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_REGION
- targetPath: thanosRuler.thanosRulerSpec.objectStorageConfig.secret.config.access_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_ACCESS_KEY_ID
- targetPath: thanosRuler.thanosRulerSpec.objectStorageConfig.secret.config.secret_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_SECRET_ACCESS_KEY
Some highlights from the values above:
- I'm enabling my global thanos discovery service by adding the
service.cilium.io/global: "true"in prometheus.thanosService.annotations - I'm setting my global label in prometheus.prometheusSpec.externalLabels
- I'm preventing prometheus from evaluating rules in prometheus.prometheusSpec.ruleSelector with a fake label. I do this because I still want PrometheusRules to be created - these will mounted into Thanos Ruler!
Edge Cluster
My edge cluster configuration is quite simple:
---
apiVersion: helm.toolkit.fluxcd.io/v2
kind: HelmRelease
metadata:
name: kube-prometheus-stack
spec:
values:
defaultRules:
create: false
alertmanager:
enabled: false
nodeExporter:
enabled: true
grafana:
enabled: false
kube-state-metrics:
metricLabelsAllowlist:
- "pods=[*]"
- "deployments=[*]"
- "persistentvolumeclaims=[*]"
prometheus:
monitor:
enabled: true
relabelings:
- action: replace
regex: ^(.*)$
replacement: $1
sourceLabels: ["__meta_kubernetes_pod_node_name"]
targetLabel: kubernetes_node
kubelet:
enabled: true
serviceMonitor:
metricRelabelings:
# Remove duplicate labels
- action: keep
sourceLabels: ["__name__"]
regex: (apiserver_audit|apiserver_client|apiserver_delegated|apiserver_envelope|apiserver_storage|apiserver_webhooks|authentication_token|cadvisor_version|container_blkio|container_cpu|container_fs|container_last|container_memory|container_network|container_oom|container_processes|container|csi_operations|disabled_metric|get_token|go|hidden_metric|kubelet_certificate|kubelet_cgroup|kubelet_container|kubelet_containers|kubelet_cpu|kubelet_device|kubelet_graceful|kubelet_http|kubelet_lifecycle|kubelet_managed|kubelet_node|kubelet_pleg|kubelet_pod|kubelet_run|kubelet_running|kubelet_runtime|kubelet_server|kubelet_started|kubelet_volume|kubernetes_build|kubernetes_feature|machine_cpu|machine_memory|machine_nvm|machine_scrape|node_namespace|plugin_manager|prober_probe|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|registered_metric|rest_client|scrape_duration|scrape_samples|scrape_series|storage_operation|volume_manager|volume_operation|workqueue)_(.+)
- action: replace
sourceLabels: ["node"]
targetLabel: instance
# Drop high cardinality labels
- action: labeldrop
regex: (uid)
- action: labeldrop
regex: (id|name)
- action: drop
sourceLabels: ["__name__"]
regex: (rest_client_request_duration_seconds_bucket|rest_client_request_duration_seconds_sum|rest_client_request_duration_seconds_count)
kubeApiServer:
enabled: true
serviceMonitor:
metricRelabelings:
# Remove duplicate metrics
- action: keep
sourceLabels: ["__name__"]
regex: (aggregator_openapi|aggregator_unavailable|apiextensions_openapi|apiserver_admission|apiserver_audit|apiserver_cache|apiserver_cel|apiserver_client|apiserver_crd|apiserver_current|apiserver_envelope|apiserver_flowcontrol|apiserver_init|apiserver_kube|apiserver_longrunning|apiserver_request|apiserver_requested|apiserver_response|apiserver_selfrequest|apiserver_storage|apiserver_terminated|apiserver_tls|apiserver_watch|apiserver_webhooks|authenticated_user|authentication|disabled_metric|etcd_bookmark|etcd_lease|etcd_request|field_validation|get_token|go|grpc_client|hidden_metric|kube_apiserver|kubernetes_build|kubernetes_feature|node_authorizer|pod_security|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|registered_metric|rest_client|scrape_duration|scrape_samples|scrape_series|serviceaccount_legacy|serviceaccount_stale|serviceaccount_valid|watch_cache|workqueue)_(.+)
# Drop high cardinality labels
- action: drop
sourceLabels: ["__name__"]
regex: (apiserver|etcd|rest_client)_request(|_sli|_slo)_duration_seconds_bucket
- action: drop
sourceLabels: ["__name__"]
regex: (apiserver_response_sizes_bucket|apiserver_watch_events_sizes_bucket)
kubeControllerManager:
enabled: true
endpoints: &cp
- 172.16.20.111
- 172.16.20.112
- 172.16.20.113
serviceMonitor:
metricRelabelings:
# Remove duplicate metrics
- action: keep
sourceLabels: ["__name__"]
regex: "(apiserver_audit|apiserver_client|apiserver_delegated|apiserver_envelope|apiserver_storage|apiserver_webhooks|attachdetach_controller|authenticated_user|authentication|cronjob_controller|disabled_metric|endpoint_slice|ephemeral_volume|garbagecollector_controller|get_token|go|hidden_metric|job_controller|kubernetes_build|kubernetes_feature|leader_election|node_collector|node_ipam|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|pv_collector|registered_metric|replicaset_controller|rest_client|retroactive_storageclass|root_ca|running_managed|scrape_duration|scrape_samples|scrape_series|service_controller|storage_count|storage_operation|ttl_after|volume_operation|workqueue)_(.+)"
kubeScheduler:
enabled: true
endpoints: *cp
serviceMonitor:
metricRelabelings:
# Remove duplicate metrics
- action: keep
sourceLabels: ["__name__"]
regex: "(apiserver_audit|apiserver_client|apiserver_delegated|apiserver_envelope|apiserver_storage|apiserver_webhooks|authenticated_user|authentication|disabled_metric|go|hidden_metric|kubernetes_build|kubernetes_feature|leader_election|process_cpu|process_max|process_open|process_resident|process_start|process_virtual|registered_metric|rest_client|scheduler|scrape_duration|scrape_samples|scrape_series|workqueue)_(.+)"
kubeProxy:
enabled: false
kubeEtcd:
enabled: true
endpoints: *cp
service:
enabled: true
port: 2381
targetPort: 2381
serviceMonitor:
scheme: https
insecureSkipVerify: false
serverName: localhost
caFile: /etc/prometheus/secrets/etcd-certs/etcd-ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/etcd-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/etcd-client-key.key
prometheus:
ingress:
enabled: true
pathType: Prefix
ingressClassName: "nginx"
hosts:
- &host-prometheus "prometheus.staging.${SECRET_DOMAIN}"
tls:
- hosts:
- *host-prometheus
thanosService:
enabled: true
annotations:
service.cilium.io/global: "true"
thanosServiceMonitor:
enabled: true
thanosIngress:
enabled: true
pathType: Prefix
ingressClassName: "nginx"
hosts:
- &host-thanos-sidecar "thanos-sidecar.staging.${SECRET_DOMAIN}"
tls:
- hosts:
- *host-thanos-sidecar
prometheusSpec:
replicas: 1
scrapeInterval: 60s
evaluationInterval: 60s
replicaExternalLabelName: __replica__
externalLabels:
cluster: sj
ruleSelectorNilUsesHelmValues: false
serviceMonitorSelectorNilUsesHelmValues: false
podMonitorSelectorNilUsesHelmValues: false
probeSelectorNilUsesHelmValues: false
retention: 2d
retentionSize: 20GB
enableAdminAPI: true
walCompression: true
secrets:
- etcd-certs
thanos:
image: quay.io/thanos/thanos:v0.38.0
# renovate: datasource=docker depName=quay.io/thanos/thanos
version: "v0.38.0"
objectStorageConfig:
secret:
type: S3
config:
insecure: false
# bucket: ""
# endpoint: ""
# region: ""
# access_key: ""
# secret_key: ""
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: longhorn
resources:
requests:
storage: 20Gi
valuesFrom:
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.bucket
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_NAME
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.endpoint
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_HOST
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.region
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_REGION
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.access_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_ACCESS_KEY_ID
- targetPath: prometheus.prometheusSpec.thanos.objectStorageConfig.secret.config.secret_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_SECRET_ACCESS_KEY
Note that I disable rule creation and alert manager - all of my rules will be centrally evaluated and we want to offload any of that overhead from our edge cluster.
If you're curious about how I enable etcd scraping on my Talos cluster, see this post.
Deploying Thanos
Finally, we'll deploy the rest of the Thanos components to the central cluster using the Bitnami Thanos chart. I chose to split out Thanos Ruler from here because the Kube-Prometheus-Stack chart has the helpful feature of converting all PrometheusRules into a ConfigMap that Ruler can automatically ingest.
---
apiVersion: helm.toolkit.fluxcd.io/v2
kind: HelmRelease
metadata:
name: thanos
spec:
values:
global:
security:
allowInsecureImages: true
image:
registry: quay.io
repository: thanos/thanos
tag: v0.38.0
objstoreConfig:
type: s3
config:
insecure: true
queryFrontend:
enabled: true
resourcesPreset: "none"
replicaCount: 3
ingress:
enabled: true
ingressClassName: traefik
hostname: &host thanos.${SECRET_DOMAIN}
tls: true
extraTls:
- hosts:
- *host
query:
enabled: true
resourcesPreset: "none"
replicaCount: 3
replicaLabel: ["__replica__"]
dnsDiscovery:
sidecarsService: kube-prometheus-stack-thanos-discovery
sidecarsNamespace: monitoring
bucketweb:
enabled: true
resourcesPreset: "none"
replicaCount: 3
compactor:
enabled: true
resourcesPreset: "none"
concurrency: 4
extraFlags:
- --delete-delay=30m
retentionResolutionRaw: 30d
retentionResolution5m: 60d
retentionResolution1h: 90d
persistence:
enabled: true
storageClass: ceph-block
size: 50Gi
storegateway:
enabled: true
resourcesPreset: "none"
replicaCount: 3
persistence:
enabled: true
storageClass: ceph-block
size: 20Gi
ruler:
enabled: false
metrics:
enabled: true
serviceMonitor:
enabled: true
valuesFrom:
- targetPath: objstoreConfig.config.bucket
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_NAME
- targetPath: objstoreConfig.config.endpoint
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_HOST
- targetPath: objstoreConfig.config.region
kind: ConfigMap
name: thanos-bucket
valuesKey: BUCKET_REGION
- targetPath: objstoreConfig.config.access_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_ACCESS_KEY_ID
- targetPath: objstoreConfig.config.secret_key
kind: Secret
name: thanos-bucket
valuesKey: AWS_SECRET_ACCESS_KEY
With that, we're practically done! A lot of Grafana dashboards, including the built-in Kubernetes views will handle the cluster label for you, so you can just start visualizing!
Member discussion